1.介绍

图为faster rcnn的rpn层,接自conv5-3
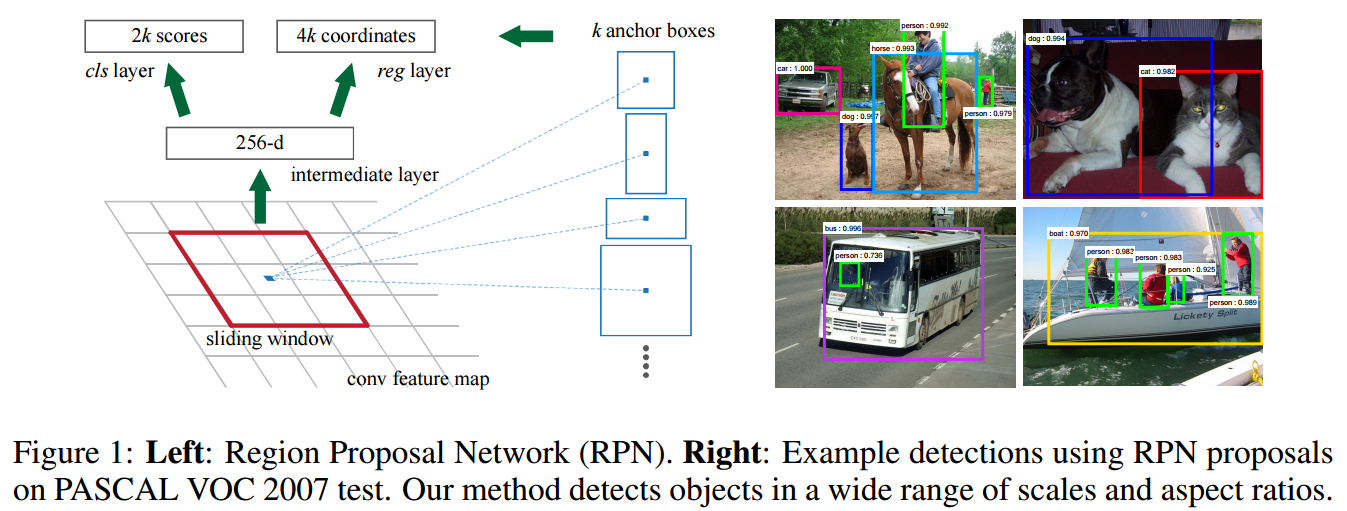
图为faster rcnn 论文中关于RPN层的结构示意图
2 关于anchor:
一般是在最末层的 feature map 上再用3*3的窗口去卷积特征。当3*3的卷积核滑动到特征图的某一个位置时,以当前滑动窗口中心为中心映射到原图的一个区域(注意 feature map 上的一个点是可以映射到原图的一个区域的,这个很好理解,感受野起的作用啊~...),以原图上这个区域的中心对应一个尺度和长宽比,就是一个anchor了。fast rcnn 使用3种尺度和3种长宽比(1:1;1:2;2:1),则在每一个滑动位置就有 3*3 = 9 个anchor。
3 关于结构 如图1所示:
关键在此,这里输出的并不是一个boundingbox的左上右下坐标,而是一个修改量(boundingbox regression)。在r-cnn的supplementary material中,给出了下面几个公式
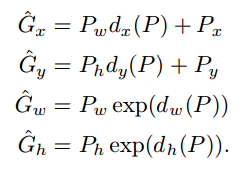 这里面的
这里面的4 关于FRCNN box回归为什么采用smooth L1 loss
对于边框的预测是一个回归问题。通常可以选择平方损失函数(L2损失)$f(x)=x^2$。但这个损失对于比较大的误差的惩罚很高。我们可以采用稍微缓和一点绝对损失函数(L1损失)$f(x)=|x|$,它是随着误差线性增长,而不是平方增长。
但这个函数在0点处不可导,因此可能会影响收敛。一个通常的解决办法是在0点附近使用平方函数使得它更加平滑。它被称之为平滑L1损失函数。它通过一个参数$\sigma$来控制平滑的区域。
5 为什么要区分前景和背景
RPN网络做的事情就是,把一张图片中,我不感兴趣的区域——花花草草、大马路、天空之类的区域忽视掉,只留下一些我可能感兴趣的区域——车辆、行人、水杯、闹钟等等,然后我之后只需要关注这些感兴趣的区域,进一步确定它到底是车辆、还是行人、还是水杯(分类问题)。。。。
你可能会看到另一对通俗易懂的词语,前景(车、人、杯)和背景(大马路、天空)。

天空和草地都属于背景

天空和马路也都是背景
到此为止,RPN网络的工作就完成了,即我们现在得到的有:在输入RPN网络的feature map上,所有可能包含80类物体的Region区域的信息,其他Region(非常多)我们可以直接不考虑了(不用输入后续网络)。
6 Region Proposal有什么作用?
1、COCO数据集上总共只有80类物体,如果不进行Region Proposal,即网络最后的classification是对所有anchor框定的Region进行识别分类,会严重拖累网络的分类性能,难以收敛。原因在于,存在过多的不包含任何有用的类别(80类之外的,例如各种各样的天空、草地、水泥墙、玻璃反射等等)的Region输入分类网络,而这些无用的Region占了所有Region的很大比例。换句话说,这些Region数量庞大,却并不能为softmax分类器带来有用的性能提升(因为无论怎么预测,其类别都是背景,对于主体的80类没有贡献)。
2、大量无用的Region都需要单独进入分类网络,而分类网络由几层卷积层和最后一层全连接层组成,参数众多,十分耗费计算时间,Faster R-CNN本来就不能做到实时,这下更慢了。